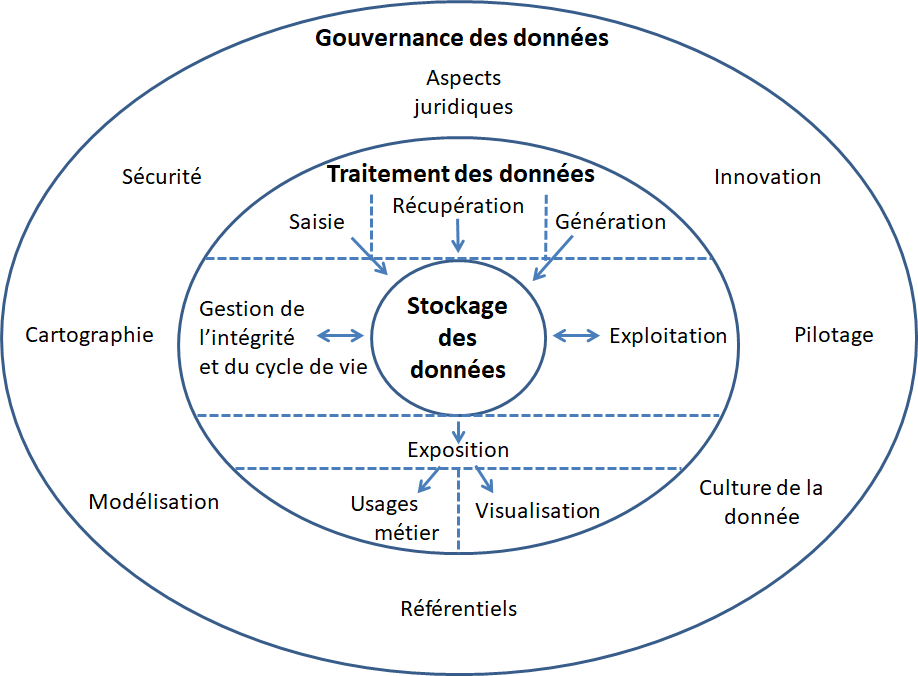
Nouvelle année que je vous souhaite excellente après cette année 2020 si particulière à tant d’égards et nouvelles perspectives... Cela fait maintenant six ans que je travaille à l’Institut national de l’audiovisuel ; six années qui ont été l’occasion de mener un magnifique projet de déploiement d’une infrastructure technique de stockage et traitement des données et d’outils de fouille de données et de textes, de modélisation et refonte des données de gestion des collections et de développement d’une culture de la donnée partagée au sein de l’établissement ; six années dont on voit aujourd’hui un premier aboutissement.
Ces six années de développement et de réflexion ont aussi été l’occasion pour moi de donner de très nombreuses formations initiales et continues autour de la question de la donnée dans différents établissements : bien-sûr l’organisme de formation de l’INA, l’ENSSIB et l’Ecole nationale des chartes. Au départ, elles étaient orientées autour des technologies du Web sémantique et elles ont peu à peu évolué vers la question des données en général pour essayer d’embrasser aujourd’hui toutes les composantes de la gouvernance des données.
J’apprécie énormément d’enseigner, de former, de partager mes réflexions sur les sujets sur lesquels je travaille, cela permet de formaliser les idées et de les mettre en ordre. Malgré tout, même si je pense que la formation fait partie intégrante de mon travail, elle n’est pas mon activité principale. Comme j’ai la chance de pouvoir choisir (mesdames et messieurs les enseignantes et enseignants, je vous admire !!), que je ne souhaite pas ressentir de la lassitude, que je souhaite que cela reste un plaisir, j’ai décidé pour cette nouvelle année de faire une pause et de laisser peu à peu la place aux personnes que j’ai formées, qui m’ont accompagné dans cette aventure des dernières années et/ou que j’ai pu croiser, à toi lecteur, peut-être !
Mais, avant de passer la main (au moins pour un temps ?), je vous propose deux choses :
- tout d’abord, je place en licence CC-BY tous mes supports de formations, vous les trouverez tous dans ce répertoire partagé sur Google drive : https://drive.google.com/drive/folders/1Uk-p8JYGDeEFAcOW9Qom-bj0p_-0Z7-d?usp=sharing N’hésitez pas, c’est là pour ça ;-) Dans la suite de ce billet, je détaille rapidement ces différents supports ;
- par ailleurs, sur une idée d’Emmanuelle, je vous propose d’organiser sous l’égide de l’Ina, une session (gratuite, évidemment…) de formation de formateurs autour de la donnée, je ne sais pas bien à quoi ressemblera cette journée, à celle qu’on souhaitera : des échanges, des présentations de supports et des objectifs pédagogiques, de la mise au point de formations… En échange, il est possible que vous soyez sollicités par les responsables de formations de l’Ina pour assurer des formations sur le sujet, en particulier par Christine Braemer avec qui nous avons mis au point un cycle de formation continue sur la question (dans la partie “Gestion des données”) et que je remercie ici pour la confiance qu’elle m’a faite ces dernières années. Si cela vous intéresse, vous pouvez me contacter par mail (gautier.poupeau@gmail.com) ou via twitter pour vous manifester. Dès que les conditions sanitaires le permettront à nouveau, nous vous contacterons pour choisir une date et mettre au point le programme de cette journée.