L'absence de contextualisation est le principal reproche adressé à RDF par ses adversaires et il est vrai qu'au premier abord cela constitue son principal défaut. En effet, le modèle du triplet à la base de RDF ne permet pas a priori d'exprimer des informations sur le contexte d'application de l'assertion, au contraire d'autres mécanismes de modélisation des connaissances qui offrent nativement des systèmes pour préciser la portée d'une assertion, à l'image, par exemple, des Topic Maps avec l'élément "scope". Ce défaut semble renforcé par deux postulats de base de RDF : chaque assertion exprimée est vraie et chaque triplet est indépendant.
Nature(s) du contexte
Les informations sur le contexte peuvent être de différentes natures :
- le contexte objectif de l'assertion, comme sa portée temporelle ou géographique, par exemple, l'assertion « Louis XIV est roi de France » n'est vraie que dans un espace temporel (en l'occurence entre 1643 et 1715) ;
- la provenance de l'assertion : l'ensemble de données dont fait partie l'assertion, son auteur, son contexte de production, la date de création...
- le degré de confiance qu'on peut lui accorder afin de déterminer si l'assertion peut être utilisée avec confiance dans son propre système de connaissances ;
- le point de vue sur une assertion, les tenants du web socio-sémantique soutiennent (non sans raison dans certains cas) qu'une assertion n'est vraie que dans un contexte social et/ou pour un groupe de personnes, c'est pourquoi le modèle Hypertopic qu'ils promeuvent permet, par exemple, d'exprimer plusieurs points de vue sur un même item (si j'ai bien compris).
Qui dit limitation, dit recherche et celle-ci ne déroge pas à la règle.
POWDER est une recommandation du W3C assez méconnu qui permet d'exprimer des métadonnées exploitables par une machine sur un ensemble de ressources. Ce protocole permet ainsi d'exprimer les caractéristiques techniques nécessaires à la consultation d'un ensemble de ressources, de restreindre l'accès à un site Web en fonction du visiteur, d'exprimer des métadonnées de provenance sur un ensemble de ressources...
La question de la provenance est au cœur d'un groupe de travail du W3C : W3C Provenance Incubator Group. Les réflexions de ce groupe ont donné lieu à un rapport datant d'avril 2010, Requirements for provenance on the Web et à une communication lors de la journée d'études dédiée à l'avenir de RDF, Provenance Requirements for the Next Version of RDF.
Par ailleurs, une ontologie pour exprimer la provenance dont la dernière version date de juillet 2010 a été mis au point par Olaf Hartig et Jun Zhao qui proposent aussi une série d'outils pour qualifier la confiance dans le Web de données.
Enfin, la notion de confiance fait l'objet, depuis deux ans, d'une conférence annuelle dont les communications en ligne vous donneront une bonne idée de l'état des recherches : SPOT: Trust and Privacy on the Social and Semantic Web.
Par ailleurs, certains mécanismes déjà présents dans les technologies du Web sémantique permettent de limiter ce problème voire de le dépasser.
La réification
La réification consiste à faire d'un triplet une ressource (donc une URI est attribué au triplet) sur laquelle des assertions peuvent être exprimées. Présent dans la spécification de RDF, ce mécanisme n'est pour autant pas recommandé, car il complique le parcours de graphe et les inférences sur le triplet d'origine et le triplet réifié. Par ailleurs, il pose de nombreux problèmes en termes de logique de description.
Le graphe nommé
Le graphe nommé est un mécanisme mis au point dès 2004 qui permet de rassembler un ensemble de triplets sous une même URI. Il ne s'agit alors plus de triplet, mais de quadruplet (quad en anglais) : <Sujet> <Prédicat> <Objet> <Graphe>.
Les usages du graphe nommé sont nombreux :
- gestion d'un ensemble de triplets (ajout, suppression, mise à jour dans un triple/quad store) ;
- indication des mentions de provenance et de confiance ;
- renforcement de la différenciation entre la notice et la ressource...
Intégrée à SPARQL, cette notion ne fait pas encore partie officiellement de la sémantique de RDF, mais, comme elle a été plébiscitée lors du « RDF Next workshop », un large consensus semble se dégager pour son intégration dans la prochaine version.
Portées géographiques et temporelles : problèmes et solutions
Mais, c'est plutôt à la portée temporelle et géographique que je voudrais m'intéresser. J'ai déjà donné l'exemple du règne de Louis XIV. On pourrait multiplier les exemples sur le rôle qu'une personne joue dans le temps : un mandat électoral et le rôle qu'il confère sont limités, un métier ne caractérise pas une personne tout au long de sa vie... D'autres problèmes se posent pour décrire une personne, par exemple, l'assertion "Jacky Bouvier est l'épouse de John Fitzgerald Kennedy" n'est pas toujours vraie, Jacky Bouvier a aussi été l'épouse d'Aristote Onassis.
D'autres domaines présentent les mêmes difficultés de modélisation, par exemple, une compétition sportive : la France est championne du monde de football en 1998 et non en 2010 (...), un tableau ou une sculpture ont été créés dans un contexte complexe (un créateur, un ou plusieurs commanditaires, un lieu d'exposition, plusieurs étapes d'élaboration...), passent de main en main au cours du temps ou sont restaurés à plusieurs reprises...
Vous l'avez compris, la contextualisation géographique et/ou temporelle est cruciale pour la modélisation de nombreux domaines. Pour dépasser cette limitation, les solutions évoquées précédemment ne semblent pas complètement adéquates, à commencer par le graphe nommé qui semblerait la solution la plus logique. Mais, un graphe nommé est commun à un ensemble de triplets, alors que la portée s'applique à un seul triplet. l'usage du graphe nommé est alors détourné et l'assimilerait à un mécanisme de réification avec les problèmes déjà évoqués.
La solution réside dans la modélisation. Il faut « retourner » le problème, c'est-à-dire dépasser la simple information d'une date, d'un rôle, d'une relation, à aborder la modélisation dans une perspective temporelle et non en centrant la réflexion sur l'entité décrite. En effet, quelle est la caractéristique commune d'un règne, d'une présidence, d'un métier ? Une période, quelle est la caractéristique commune d'une naissance, un décès, une compétition sportive, une publication ? Une date. Si les aspects temporels sont à la fois le problème et la caractéristique commune, pourquoi ne seraient-ils pas aussi la solution ?
Or, que caractérisent une période ou une date ? Ou, pour le dire autrement, quel est le type d'entités dont la caractéristique principale est une période ou une date ? Un Événement. Une naissance, un décès, un mandat, une compétition sportive, une publication, toutes ces entités sont des types d'événements dans lesquels sont impliqués des personnes, des équipes, des objets...
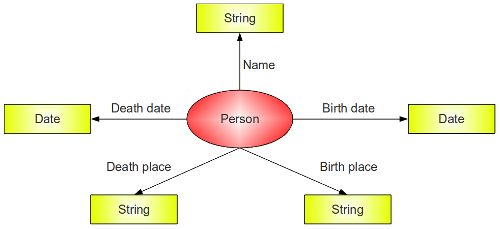
Représentation graphique de la modélisation orientée "entité"
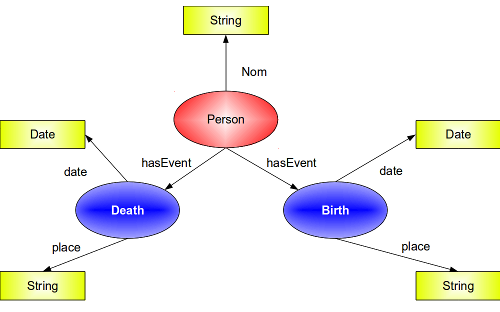
Représentation graphique de la modélisation orientée "événement"
Cette solution présente plusieurs avantages :
- l'ensemble des informations concernant l'événement (date, lieu, autres entités impliquées, lien avec d'autres événements) sont reliées à une ressource distincte, à l'inverse de la modélisation orientée « entité » dans laquelle on peut trouver plusieurs triplets indépendants pour qualifier la même ressource. Ainsi, dans Dbpedia, il existe une propriété <http://dbpedia.org/ontology/birthDate>, une propriété <http://dbpedia.org/ontology/birthPlace>, une propriété <http://dbpedia.org/ontology/deathDate>, une propriété <http://dbpedia.org/ontology/deathPlace> reliés à la même entité personne.
- les différentes propriétés utilisés pour désigner la date, le lieu, les agents impliqués sont les mêmes quelque soit le type d'événement. Cela permet d'optimiser et de faciliter les recherches et le croisement de données.
- la modélisation est plus proche de notre réalité, moins caricaturale ;
En revanche, cette solution a tendance à compliquer la modélisation à l'excès au point d'alourdir inutilement le modèle. Il faut donc parfois savoir peser le pour et le contre avant d'adopter cette méthode. Par exemple, Dbpedia, cherchant à rester le plus proche possible de Wikipedia, n'a pas adopté ce principe et cherche la simplicité dans le mapping et dans le modèle.
Les ontologies pour décrire un événement
Modéliser le temps est certainement un des exercices de modélisation les plus complexes, car sa perception dépend de nombreux facteurs physiques et sociologiques, comme le rappelait Karl récemment. De plus, les enjeux de la modélisation d'événements sont très nombreux. Outre celui déjà mis en lumière, la modélisation orientée "événement" est aussi au cœur de la description des images fixes et animées qui constitue un des défis les plus prometteurs de la recherche d'informations dans les prochaines années. Il n'est donc pas étonnant de trouver plusieurs ontologies qui permettent de décrire les événements :
- The Event Ontology mise au point par Yves Raimond et Samer Abdallah ;
- LODE : Linking Open Descriptions of Events mis au point par Ryan Shaw, Raphaël Troncy et Lynda Hardman ;
- Dublin Core terms, qui contient une classe Event ;
- RDF Calendar mis au point Dan Connolly et Libby Miller ;
- Le CIDOC-CRM, modèle conceptuel pour décrire les objets patrimoniaux contient un certain nombre de classes et de propriétés liés aux événements ;
- EventsML-G2, schéma XML qui fait partie des standards IPTC...
Je ne vais pas m'amuser à les comparer, ce serait trop long, je ne suis pas sûr d'en avoir les compétences et d'autres ont déjà fait cela mieux que je ne le ferais (en particulier slides 18 à 25).
A titre personnel, j'utilise les deux premières ontologies citées, car elles sont liées de manière étroite à d'autres ontologies très utilisées comme FOAF, Time Ontology, Dublin Core, GEO. LODE présente l'avantage, de par sa nouveauté, d'être alignée avec toutes les autres ontologies, ce qui permet de gérer l'interopérabilité via des mécanismes d'inférence.
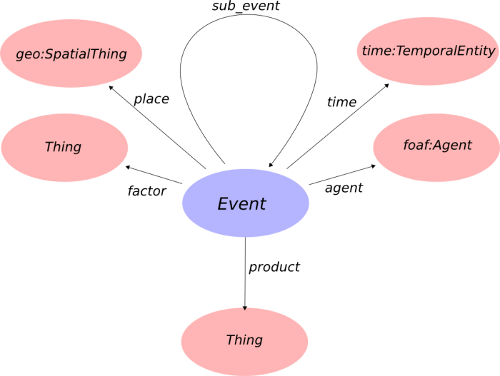
Représentation graphique de l'Event Ontology
Une dernière ontologie occupe une place à part. Elle n'est pas spécifiquement dédiée à la description d'événements, mais elle étend le concept à la description d'une biographie : BIO vocabulary mise au point par Ian Davis. Elle permet ainsi de résoudre les différents problèmes évoqués dans les exemples précédents. Chaque type d'événement (naissance, mariage, décès, divorce...) est une sous-classe d'une classe unique bio:event, elle-même sous-classe des classes "Event" présentes dans la plupart des différents vocabulaires listés précédemment. Par ailleurs, Ian Davis a ajouté différents types de relations entre les événements : événement précédent, événement suivant, événement "concluant" très utiles pour déterminer une suite d'événements et leurs conséquences, par un exemple : un événement de type "Marriage" a pour événement concluant un événement de type "Death"...
Transformer des assertions de Dbpedia en événement
Même si la modélisation de Dbpedia n'est pas orientée "Événement", il est toujours possible d'extraire et de transformer ces données pour les présenter sous une forme plus facile à exploiter.
Le mot-clé CONSTRUCT en sparql
Pour ce faire, aucun code informatique n'est nécessaire, une requête SPARQL suffit pour effectuer ces deux actions. Mais, en lieu et place du SELECT utilisé le plus couramment, nous allons utiliser le mot-clé CONSTRUCT. Moins connu que SELECT, CONSTRUCT est pourtant essentiel pour tous les développeurs qui souhaitent manipuler du RDF. Il permet, en effet, à partir d'un ensemble de triplets de construire un autre ensemble de triplets. Il est ainsi utilisé pour récupérer un ensemble de triplets afin de manipuler localement, transformer un ensemble de triplets, un peu dans le même esprit que XSLT pour du XML, créer de nouveaux triplets en mixant deux sources de données, effectuer des inférences. Bref, CONSTRUCT est l'outil indispensable du couteau suisse du développeur RDF.
Une requête CONSTRUCT est composée de deux parties :
- le patron des triplets à obtenir ;
- la requête en elle-même ;
Par exemple, si je souhaite récupérer l'ensemble des triplets d'un ensemble de données depuis un SPARQL endpoint, j'effectuerai la requête suivante :
CONSTRUCT {
?s ?p ?o
}
WHERE {
?s ?p ?o
}
Si je souhaite effectuer un mapping pour changer une propriété par une autre propriété, j'effectuerai la requête suivante :
PREFIX dc: <http://purl.org/dc/elements/1.1/>
PREFIX dcterms: <http://purl.org/dc/terms/>
CONSTRUCT {
?s dc:date ?o
}
WHERE {
?s dcterms:dateSubmitted ?o
}
CONSTRUCT pour extraire les événements de dbpedia
Dans le cas qui nous intéresse, je souhaite construire des événements à partir des informations sur la naissance et le décès des rois de France, j'effectue donc la requête CONSTRUCT suivante
PREFIX event: <http://linkedevents.org/ontology/>
PREFIX bio: <http://purl.org/vocab/bio/0.1/>
CONSTRUCT {
`iri (bif:concat ("http://example.org/",str(?king),"/naissance"))`
a bio:Birth;
dc:date ?date;
dc:description `str (bif:concat ("Birth of ", str (?label)))`;
bio:principal ?king;
bio:parent ?mother;
bio:parent ?father;
bio:place ?place;
a event:Event;
event:atPlace ?place;
event:atTime [ <http://www.w3.org/2006/time#inXSDDateTime> ?date];
event:involvedAgent ?king;
event:involvedAgent ?mother;
event:involvedAgent ?father.
}
WHERE {
?king a <http://dbpedia.org/ontology/Person>;
rdfs:label ?label.
{{?king a <http://dbpedia.org/class/yago/FrenchMonarchs>}
UNION {?king a <http://dbpedia.org/class/yago/KingsOfFrance>}}
?king <http://dbpedia.org/ontology/birthDate> ?date.
OPTIONAL {?king <http://dbpedia.org/ontology/birthPlace> ?place.}
OPTIONAL {?king <http://dbpedia.org/ontology/father> ?father.}
OPTIONAL {?king <http://dbpedia.org/ontology/mother> ?mother.}
FILTER (lang(?label)="en")
}
Plusieurs remarques s'imposent :
- j'ai utilisé certaines fonctions propres à Virtuoso, le triple store utilisé par Dbpedia, pour construire de nouvelles URI à la volée à mes ressources à partir des URIs de dbpedia et construire une description (sur ce coup-là, j'ai un peu triché, j'avoue...) ;
- les triplets obtenus utilisent l'ontologie LODE et l'ontologie BIO ;
- certaines assertions sont optionnelles, le sparql endpoint ne renverra un triplet que si la donnée existe vraiment.
Il suffit ensuite de faire varier les propriétés dans la requête pour disposer des informations de décès, de couronnement ou de mariage.
Résultat
A l'issue de cette extraction de Dbpedia, j'ai retravaillé dans un triple store localement les données en utilisant de la même façon des requêtes SPARQL CONSTRUCT pour obtenir ce résultat avec l'ontologie LODE sérialisé avec la syntaxe turtle :
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> .
@prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#> .
@prefix dc: <http://purl.org/dc/terms/> .
@prefix event: <http://linkedevents.org/ontology/>
@prefix dbpedia: <http://dbpedia.org/resource/>
@prefix time: <http://www.w3.org/2006/time#>
<!-- Événement correspondant à la naissance de Louis XIV -->
<http://linkedevents.org/Louis_XIV_of_France/Birth>
event:atPlace dbpedia:Ch%C3%A2teau_de_Saint-Germain-en-Laye ;
event:atTime [
a time:DateTimeInterval ;
time:hasDateTimeDescription [
a time:DateTimeDescription ;
time:day "5" ;
time:month "9" ;
time:unitType time:unitDay> ;
time:year "1638"
]
];
event:involvedAgent dbpedia:Anne_of_Austria, dbpedia:Louis_XIII_of_France,
dbpedia:Louis_XIV_of_France ;
dc:description "Birth of Louis XIV of France" ;
dc:source <http://dbpedia.org> ;
a event:Event ;
rdfs:label "Birth of Louis XIV of France" .
<!-- Événement correspondant au couronnement de Louis XIV -->
<http://linkedevents.org/resource/Louis_XIV_of_France/Coronation>
event:atTime [
a time:DateTimeInterval ;
time:hasDateTimeDescription [
a time:DateTimeDescription ;
time:day "7" ;
time:month "6" ;
time:unitType time:unitDay> ;
time:year "1654"
]
] ;
event:involvedAgent dbpedia:Louis_XIV_of_France ;
dc:description "Coronation of Louis XIV of France" ;
dc:source <http://dbpedia.org> ;
a event:Event ;
rdfs:label "Coronation of Louis XIV of France" .
<!-- Événement correspondant au décès de Louis XIV -->
<http://linkedevents.org/resource/Louis_XIV_of_France/Death>
event:atPlace dbpedia:Palace_of_Versailles ;
event:atTime [
a time:DateTimeInterval ;
time:hasDateTimeDescription [
a time:DateTimeDescription ;
time:day "1" ;
time:month "9" ;
time:unitType time:unitDay> ;
time:year "1715"
]
] ;
event:involvedAgent dbpedia:Louis_XIV_of_France ;
dc:description "Death of Louis XIV of France" ;
dc:source <http://dbpedia.org> ;
a event:Event ;
rdfs:label "Death of Louis XIV of France" .La modélisation orientée "événement" permet donc de donner plus de détails : le lieu, décomposition de la date, les personnes impliquées, la source des informations, une description human readable. En revanche, cette ontologie n'étant pas spécifiquement dédiée à la description biographique, il manque certains niveaux de détails, comme, par exemple, le rôle joué par chaque "agent" dans l'événement "naissance", un typage plus fin des événements. Dans ce cas, l'ontologie BIO est beaucoup plus fine :
@prefix foaf: <http://xmlns.com/foaf/0.1/> .
@prefix bio: <http://purl.org/vocab/bio/0.1/> .
@prefix dbpedia: <http://dbpedia.org/resource/>
@prefix linkedevent: linkedevent:>
dbpedia:Louis_XIV_of_France
foaf:name "Louis XIV de France"@fr ;
bio:child dbpedia:Fran%C3%A7oise-Marie_de_Bourbon,
dbpedia:Louis%2C_Count_of_Vermandois,
dbpedia:Louis%2C_Dauphin_of_France_%281661%E2%80%931711%2,
dbpedia:Louis_C%C3%A9sar%2C_Count_of_Vexin,
dbpedia:Louis_Fran%C3%A7ois%2C_Duke_of_Anjou,
dbpedia:Louise-Fran%C3%A7oise_de_Bourbon,
dbpedia:Louise_Marie_Anne_de_Bourbon,
dbpedia:Marie_Anne_de_Bourbon,
dbpedia:Philippe_Charles%2C_Duke_of_Anjou,
dbpedia:Princess_Anne_%C3%89lisabeth_of_France,
dbpedia:Princess_Marie_Anne_of_France,
dbpedia:Princess_Marie_Th%C3%A9r%C3%A8se_of_France_%281667%E2%80%931672%29 ;
bio:event linkedevent:Louis_XIV_of_France/Birth,
linkedevent:Louis_XIV_of_France/Coronation,
linkedevent:Louis_XIV_of_France/Marriage1,
linkedevent:Louis_XIV_of_France/Marriage2,
linkedevent:Louis_XIV_of_France/Death,
linkedevent:Louis_XIV_of_France/Burial.
<!-- événement correspondant à la naissance de Louis XIV -->
linkedevent:Louis_XIV_of_France/Birth
dc:description "Birth of Louis XIV of France" ;
bio:date "1638-09-05"^^<http://www.w3.org/2001/XMLSchema#date> ;
bio:parent dbpedia:Anne_of_Austria, dbpedia:Louis_XIII_of_France ;
bio:place dbpedia:Ch%C3%A2teau_de_Saint-Germain-en-Laye ;
bio:principal dbpedia:Louis_XIV_of_France ;
a bio:Birth .
<!-- événement correspondant au couronnement de Louis XIV -->
linkedevent:Louis_XIV_of_France/Coronation
dc:description "Coronation of Louis XIV of France" ;
bio:date "1654-06-07"^^<http://www.w3.org/2001/XMLSchema#date> ;
bio:principal dbpedia:Louis_XIV_of_France ;
a bio:Coronation .
<!-- événement correspondant au premier mariage de Louis XIV -->
linkedevent:Louis_XIV_of_France/Marriage1
dc:description "Marriage of Louis XIV of France and
Maria Theresa of Spain" ;
bio:partner dbpedia:Louis_XIV_of_France, dbpedia:Maria_Theresa_of_Spain ;
a bio:Marriage .
<!-- événement correspondant au second mariage de Louis XIV -->
linkedevent:Louis_XIV_of_France/Marriage2
dc:description "Marriage of Louis XIV of France and
Françoise d'Aubigné, marquise de Maintenon"
bio:partner dbpedia:Fran%C3%A7oise_d%27Aubign%C3%A9%2C_marquise_de_Maintenon,
dbpedia:Louis_XIV_of_France ;
a bio:Marriage .
<!-- événement correspondant au décès de Louis XIV -->
linkedevent:Louis_XIV_of_France/Death
dc:description "Death of Louis XIV of France" ;
bio:date "1715-09-01"^^<http://www.w3.org/2001/XMLSchema#date> ;
bio:place dbpedia:Palace_of_Versailles ;
bio:principal dbpedia:Louis_XIV_of_France ;
a bio:Death .
<!-- événement correspondant à l'enterrement de Louis XIV -->
linkedevent:Louis_XIV_of_France/Burial
dc:description "Burial of Louis XIV of France" ;
bio:place dbpedia:Saint_Denis_Basilica ;
bio:principal dbpedia:Louis_XIV_of_France ;
a bio:Burial .Même si, dans ce cas, les données sont plus précises, elles pourraient encore gagner en précision (date des deux mariages, lien vers les événements qui mettent fin au mariage, lien entre les événements), mais elles sont, en l'état, tributaires des données de Dbpedia et montrent précisément les problèmes que pose une modélisation orientée "entité". Pour autant, grâce à cette modélisation, il est beaucoup plus facile d'enrichir et d'améliorer les données sans avoir besoin de multiplier les propriétés ad hoc.
Commentaires
Très intéressant! Il est vrai que le modèle basé sur les événements est plus séduisant que la création de propriétés ad-hoc à la chaine. Même si il me semble que DBPedia a opté pour cette solution pour des raisons d'automatisme. Chaque entrée d'une InfoBox peut facilement être convertie en propriété+valeur (chaine) sans nécessiter d'information additionelle pour détecter la nature de la propriété.
Juste une remarque concernant le CONSTRUCT. La construction des URI avec "iri (bif:concat ("http://example.org/",str(?king),"/naissance"))" donne lieu à des URI du genre "<http://example.org/http://dbpedia.org/resource/Louis_XVI_of_France/naissance>". Alors que "iri (bif:concat ("http://example.org/",str(?label),"/naissance"))" permet de ne retenir que le nom :-)
Merci, Christophe.
"Même si il me semble que DBPedia a opté pour cette solution pour des raisons d'automatisme." Clairement, la maintenance du mapping et des algorithmes de conversion sont largement simplifiés en restant le plus proche possible de la structure des infobox, sans compter la génération des URIs qui serait un véritable casse-tête.
Concernant l'URI, c'est de la paresse, comme tu as pu le constater, cela a été corrigé dans les exemples finaux (à la main, je dois l'avouer). Ta proposition est séduisante, mais elle ne me satisfait pas complètement à cause des espaces blancs qui sont une horreur une fois encodé dans une URI, la meilleure solution est de placer une regexp ce qui, je suis sûr, doit être possible. En revanche, ta remarque m'amène une question, peut-on avoir une URI du type http://exemple.org/http://example2.org, je vais vérifier cela.
Intéressante solution, mais qui ne lève pas ma réticence face à RDF, dont l'ontologie "réaliste" implicite, fondée sur une construction de triplets indépendants (et une acception de "prédicat" trop sommaire, à mon avis) me semble passer à côté des résultats d'années de recherche en logique, linguistique et épistémologie. Mais sans doute suis-je influencé par la relecture attentive que je viens de faire du livre de Pierre Jacob, L'intentionnalité: problèmes de philosophie de l'esprit, Odile Jacob, 2004, 978-2738115409.
La description d'un événement "ponctuel" à partir de time:DateTimeDescription risque de poser vite un problème de référence "universelle", en particulier pour l'accès à des entités couramment désignées sous la forme de descriptions définies, comme l'Académie française, la famille Hugo (souvenirs de problèmes d'indexation pour l'édition de la correspondance Hugo…).
Sans doute des solutions à chercher du côté des logiques floues — au prix de l'indépendance des triplets ?
Je suis bien incapable de te répondre sur l'aspect théorique, pour tout t'avouer, cela ne m'intéresse pas, à titre personnel, de pousser la réflexion dans cette perspective (même si ma curiosité ne demande qu'à être assouvi) et je laisse cela aux chercheurs (Fabien, Alexandre M., Christophe et les autres, je serai ravi d'avoir votre contribution sur cette question). Néanmoins, ton commentaire appelle plusieurs réflexions de ma part.
Le but des technologies du Web sémantique ne me semble pas à proprement parler de capturer la réalité ou de modéliser la connaissance du monde, mais de proposer un ensemble d'outils, de méthodes, de formalismes pour permettre l'échange entre les machines dans un espace en réseau (le Web) de données structurées.
Cet objectif passe par l'utilisation de résultats des recherches provenant effectivement aussi bien de la linguistique, de la logique de description (d'où le mot sémantique...), de la théorie des graphes que des bases de données.
Mais, avant tout, cela passe par une exigence de standardisation et c'est cela qui m'intéresse beaucoup plus car la standardisation permet l'émergence d'un écosystème d'outils et d'implémentations qui est censé faciliter (ou fluidifier) le déploiement d'un technologie. Surtout, une standardisation, à la différence de la recherche, est le fruit d'un compromis entre la recherche (et compromis entre les différents domaines : logiciens contre théoriciens des graphes par exemple...), justement, mais aussi les contingences de production, de développement et d'implémentation et les impératifs économiques et financiers (même si les technos du Web sémantique n'ont pas été concernés vraiment par ces aspects jusqu'à maintenant, ça commence à arriver).
De ce point de vue, deux remarques encore : tout d'abord, la standardisation vécue par certains comme un poids est, au contraire, une chance car elle peut faire gagner beaucoup de temps en évitant d'avoir à inventer son propre système et les limites inhérentes au compromis ne sont souvent que des prétextes, d'autre part, tu cites les recherches effectuées en logique, linguistique et épistémologie, mais je te renvoie la question, ces recherches ont-elles débouchées sur des technologies fiables, matures, répondant à la charge et aux exigences de plus en plus importantes de nos clients ? Je suis preneur dans ce cas, car, quand je vois les modèles sous-jacents aux bases dites NoSQL (du clé-valeur dans 80% des cas) qui font tant parler en ce moment et qui sont au cœur des grosses machineries comme Facebook, Twitter et autres, je m'interroge si ce n'est plus. Quant à l'analyse linguistique, la montée en puissance des méthodes probabilistes dénote d'un certain échec des grammaires formelles complexes, non ?
Un autre point est fondamental : c'est la courbe d'apprentissage pour l'appropriation d'une technologie par l'industrie (pour faire simple et pour faire large). Il ne faut pas oublier une chose : si HTML a fonctionné, c'est de par sa simplicité, mais HTML est une horreur en termes de structuration de l'information et a fait s'étrangler tous les spécialistes de SGML à l'époque. D'ailleurs, lorsqu'il s'est agi d'améliorer ces aspects avec la belle cathédrale XHTML 2 (et Xforms et les autres), il y a eu une véritable levée de boucliers des développeurs de navigateurs au prétexte que cela allait troubler les utilisateurs, que c'était trop compliqué à implémenter, que cela ferait tomber les perfs..., au point que le W3C a fait machine arrière et qu'on se retrouve dans HTML 5 avec des aberrations datant des débuts de HTML. De là à dire que simplicité et implémentation industrielle (cf. ma remarque ci-dessus sur NoSQL) demande parfois des compromis en termes d'état de l'art, il n'y a qu'un pas que je franchis allègrement. De plus, quand je vois la courbe d'apprentissage demandée pour prendre en main les technologies du Web sémantique, bien supérieur à celle de HTML, CSS voire XML et XSL, je m'inquiète du bagage conceptuel nécessaire à la compréhension des problématiques que tu exposes (et j'en suis le premier exemple :-) ).
Sur la problématique de la "référence universelle", je t'invite à regarder en détail l'ontologie 'Time Ontology" très complète, utilisée par la plupart des ontologies d'événements, qui dépasse très largement la description de time:DateTimeDescription et qui devrait répondre à un certain nombre de tes interrogations. J'en fais une utilisation dans mes exemples qui ne lui rend pas hommage.
Désolé, j'ai été un peu long comme d'habitude, mais cela me paraît important de ne jamais perdre de vue que ces technologies sont prévues pour être déployées sur des échelles très importantes (pour lesquelles, au passage, les technos ne sont pas forcément matures...) et que le souci de standardisation me semble un argument à ne jamais négliger.
Tout à fait d'accord sur l'importance des standards, et le rappel des objectifs (et problèmes) concrets des technologies du web "sémantique". Je suis moi aussi, par ailleurs, persuadé que la théorie des graphes et les approches statistiques fournissent un cadre plus opérationnel pour avancer dans ce domaine : les résultats en traitement automatique du langage sont bien là pour le prouver.
Cela dit, je pense que la recherche en logique et en linguistique a fourni des explications concrètes, des résultats proprement scientifiques, qui expliquent les échecs ou résultats décevants d'un certain nombre de modèles, "logicistes", ou déterministes, par exemple.
(L'histoire de la philosophie fournit quelques exemples de résultats bien analysés, de pistes qu'il n'y a plus lieu de suivre, de la characteristica universalis de Leibnitz, à Frege et Russell.)
Dans le cadre des technologies en question, il est crucial d'avoir des outils pour évaluer la pertinence et l'efficacité des standards en cours de développement ou d'adoption. Les constats de l'épistémologie sur les difficultés, les limites et les avantages des langages formels, de leurs relations avec le langage et le symbolique en général devraient permettre au moins de prédire les limites d'application de standards comme RDF, ou d'encourager l'émergence de modèles plus complexes (fonctions multivaluées, graphes non orientés) et d'outils de calcul adaptés, aboutissant aussi bien à la représentation symbolique "d'états du monde", (le "I" d'information, dans TIC), qu'à des décisions d'(inter)action et de communication (le "C"). C'est ce que nous attendons sans doute des technologies numériques ?
Bonjour Alain,
Une petite voix m'a soufflé d'aller voir ce qui se passait ici ;)
Je vais non pas répondre (de manière définitive) mais discuter certains points que tu soulèves ici fort justement.
- Sur le réalisme de l'ontologie de RDF : c'est un point que tu ne développe pas vraiment par conséquent prenons les choses de biais. Qu'une ontologie soit réaliste, à cette échelle, ne me choque pas. Partir d'un point de vue réaliste permet ensuite de le relativiser. Partir d'emblée dans une perspective non-réaliste conduit en revanche à des résultats à mon sens beaucoup plus hasardeux.
- Concernant le prédicat, je connaît tes réticences et je les partages. Il me semble d'ailleurs que c'est un point qui pourrait/devrait être revu dans la perspectives des discussions autour de RDF 2.0.
Tu écris également ceci :
"me semble passer à côté des résultats d'années de recherche en logique, linguistique et épistémologie. Mais sans doute suis-je influencé par la relecture attentive que je viens de faire du livre de Pierre Jacob, L'intentionnalité: problèmes de philosophie de l'esprit, Odile Jacob, 2004, 978-2738115409."
Quelle logique ? Quelle linguistique ? Je doute, hélas, que la logique suffise à trancher les questions qui se posent à nous. Gautier a dit pourquoi à sa façon. Des logiciens de la classe de Pat Hayes se penchent sur RDF, il ne faut pas croire que l'ignorance domine ici. La logique a d'ailleurs ses propres problèmes, la linguistiques aussi, et il est difficile de leur faire jouer le rôle d'arbitre impartial, à l'abri des soubresauts qui agitent tous les champs du savoir.
Tu parles du contexte épistémologique, mais peut-être les travaux des téléosémanticiens, dont Pierre Jacob (je pense à Dretske, Millikan, etc.), sont-ils en butte à un contexte épistémologique nouveau ! Dans lequel les noms propres ne sont plus des noms propres mais des URIs déréférencable... Dans lequel les conditions de la signification ont changé. Hayes a récemment parlé de "Blogic" pour qualifier sa proposition d'une logique adaptée au Web (contraction de Web Logic).
La question est de savoir si l'artefact, dans sa matérialité, fût-il le ubiquitaire comme le Web, laisse indemne la logique, le langage, l'épistémologie, la philosophie, etc. Personnellement, je ne le pense pas. Je crois qu'une médiation s'instaure nécessairement. Il y a, de ce côté-là aussi, du constituant, comme le dirait Bernard Stiegler. D'ailleurs, on aurait tort de ne considérer que "la logique", universelle et souveraine, quand la réalité nous met au prise avec des logiqueS, au pluriel (cf. Van Heijenoort et Hintikka sur ce point : Language as Calculus vs. Language as Universal Medium).
De même qu'il n'y a pas LE langage comme un donné pur, mais une forme historicisée, en dialogue permanent avec l'évolution des conditions sociales, techniques, et autres.
Venons-en maintenant à ce qui, selon moi, constitue l'essentiel. Tu écris ceci :
"La description d'un événement "ponctuel" à partir de time:DateTimeDescription risque de poser vite un problème de référence "universelle", en particulier pour l'accès à des entités couramment désignées sous la forme de descriptions définies, comme l'Académie française, la famille Hugo (souvenirs de problèmes d'indexation pour l'édition de la correspondance Hugo…)."
Et tu as raison de parler de descriptions définies. Maintenant, cette question est-elle celle de RDF ? RDF, à mon sens, ne pèse guère à côté des URIs et de la notion de ressource.
Savoir comment une URI signifie (et l'on retrouve la question des description définie) voilà la vraie question. Référence directe ? Descriptions définies ? Peut-être les oppositions qui étaient de mise sont-elles aujourd'hui subtilement subvertie dans un contexte épistémologique nouveau.
Disposer d'une ontologie de la ressource viable et prenant en compte ses multiples dimensions temporelles (perdurants, endurants, autre chose ?).
En ce sens, l'on affronte à la fois la question sémantique de la signification, et la question ontologique (la référence opérant peut-être une couture - et non une coupure ;) - entre les deux).
D'où, d'ailleurs, pour ceux qui me connaissent, mon insistance sur l'ontologie IRW de Valentina Presutti et Harry Halpin, ontologie de la ressource, fondamentale, mais qui n'épuise pas le sujet malgré l'admiration que je porte à ces travaux.
Bien sûr, c'est question mériterait d'être davantage développées au plan philosophique, et c'est pourquoi <réclame>je vous donne rendez-vous le 16 octobre prochain à la Sorbonne pour PhiloWeb 2010 </réclame> ;)
"Disposer d'une ontologie de la ressource viable et prenant en compte ses multiples dimensions temporelles (perdurants, endurants, autre chose ?)..." voilà l'autre face d'une même question.
Je m'étais coupé, mes désolées ;)
Je suis concepteur d'un projet communautaire, open source, hébergé sur Developpez.com (Nom du projet : Moterako) dont la contextualisation des données et des informations constitue un des fondements conceptuels. J'apporte ici quelques éléments de mon projet pour compléter/discuter de cet article que je trouve fort intéressant.
J'aimerais apporter quelques remarques sur la nature des contextes, qui ne peuvent être détachés des informations (et des données) pour en extraire un sens (des ontologies, des connaissances) :
La contextualisation est à la base du concept du projet Moterako, j'invite les lecteurs à y jeter un coup d’œil ou à y participer. Une version de référence est disponible en ligne sur : http://demo.java.developpez.com:8888/moterako/
Les détails du projet sont sur : http://projets.developpez.com/projects/moterako
Bonne lecture,