Comme le rappelait très justement Dominique Cardon dans son interview du vendredi 6 janvier sur France Inter :
« [...]il faut faire attention, les algorithmes, c’est idiot, c’est une procédure statistique un peu bête qui utilise des données pour faire un grand calcul massif[...] »
Comme l'a expliqué Dominique Cardon malgré les coupures incessantes d'Ali Baddou (et comme je l'avais fait beaucoup plus modestement), l'algorithme n'est pas une entité en soi : ce n'est qu'un code source mis au point par un humain qui détermine la « procédure statistique » exécuté sur et grâce à des données. Ces dernières sont donc d'une importance fondamentale.
Il y a presque 10 ans, Christian Fauré faisait état sur son blog d’une certaine déception des organisations devant les résultats des outils de reporting et de Business Intelligence au regard de l’investissement effectué pour les déployer. Il revenait alors sur un point essentiel : ce genre d’outils ne donne leur plein potentiel que si les données sont propres, le fameux adage en traitement des données : « shit in, shit out ».
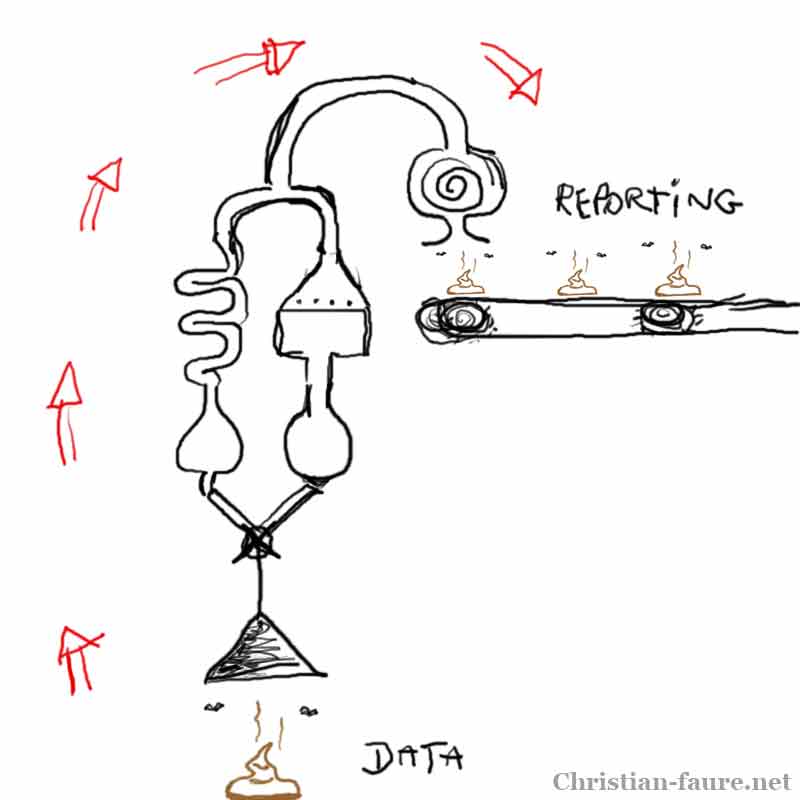
Dix ans plus tard, on sent souvent poindre la même déception concernant le Big data car rien a changé pour le traitement des données : les algorithmes ont plus que jamais besoin de données « propres » pour fonctionner. Par exemple, la pertinence des systèmes de catégorisation automatique dépend presque intégralement de la qualité du corpus utilisé pour effectuer l’entraînement du système.
Ainsi, on voit apparaître régulièrement des statistiques montrant que les « data scientists » passent presque 80% de leur temps à sélectionner, nettoyer et préparer les données (cf. ces articles du New York Times de 2014 et de Forbes en 2016). Vous y réfléchissez à deux fois avant de faire cet investissement quand vous savez le prix de ce genre de compétence. Or, ce travail n’est pas plus « sexy » aujourd’hui qu’il y a dix ans pour reprendre les termes employés par Christian. En revanche, étant donné la valeur (réelle ou supposée…) créée par ces algorithmes, des solutions commencement à émerger et la préparation des données (on parle aussi de data wrangling en anglais) est peu à peu devenue un enjeu jusqu’à devenir une des tendances annoncée du « Big Data » pour 2017.

{kind=link}